Managing tens of thousands of messages in deadletter queues at Togai
I like learning new stuff - anything, including technology. I love tinkering with new tools, systems and services, especially open source projects
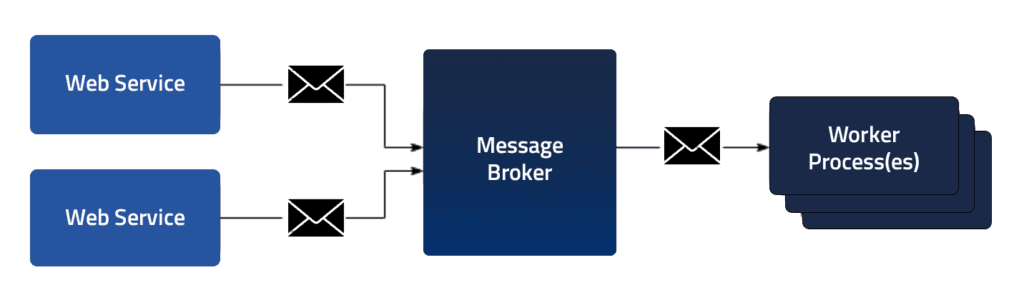
At Togai, we have a microservices architecture. When some specific events happen, we push the event information to a message broker (NATS) so that other services that are interested in the event can consume it and do its work/processing.
Whenever there's a message broker/message queue system, from which messages are consumed and processed, there's this possibility of error occurring during the processing of the message. Some of these errors are intermittent errors or special kinds of errors in which case when the system retries to process the message the error will not happen. It may take a few retries sometimes, for it to work; you know, the worst-case scenarios. Such errors are usually called retriable errors, or such messages with processing issues are called retriable messages which when retried (to process) will work just fine.
Of course, the system cannot keep retrying infinitely, right? Also, not all erroneous messages can be retried, some issues just won't get solved with a retry and would probably need human intervention, maybe because there's some issue in the system - the code, configuration, etc. Such erroneous messages are called non-retriable erroneous messages.
So, to solve for avoiding infinite retries, there's a concept of a maximum number of retries that people usually define. And people also retry in exponential backoff intervals, for example, the first retry is after 1 minute, the second retry is after 2 minutes, the third retry is after 4 minutes and so on. Nth retry would be after 2^(N-1) minutes. This was just an example of an exponential backoff algorithm/method for retries
So, now we have a solution for infinite retries and we also don't retry processing the message immediately or in fixed intervals but instead retry processing with exponential backoff intervals
Now, what happens when the maximum number of retries is reached - say when an erroneous message is non-retriable, or it's retriable but the number of retries has reached a maximum? Now what? In such cases, messages get pushed into a queue called Deadletter Queue - in short, it's called DLQ.
Before we go into DLQ. One short note. While developing a system, the developer may be able to segregate and code for retriable and non-retriable messages and handle them appropriately as desired. But sometimes some issues/errors may be unknown (or hidden) at the time of developing the system, so, you will notice them probably only while running the system - worst case scenario in production, best case scenario in development machine during development, or in staging or sandbox or similar testing environments. Such messages will just be retried regardless of if it's retriable or not which sometimes only developers can see and say. Hopefully, AI will start helping here too ;)
Now, back to DLQs. At Togai, we use DLQs to push messages that have reached a maximum number of retries. We use AWS SQS as our DLQ to push our DLQ messages. We get alerts on Slack 🚨 ‼️ 🔔, on our on-call channels, when the number of messages in various DLQs increases
Below are examples of how the alerts look in various environments for various DLQs we have for various services and/or use cases -
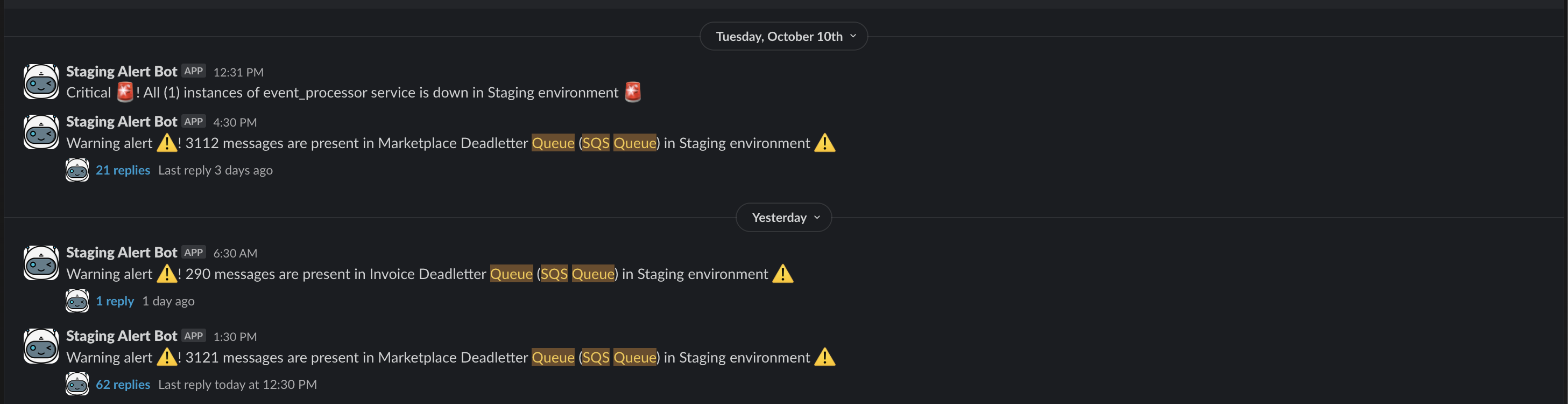

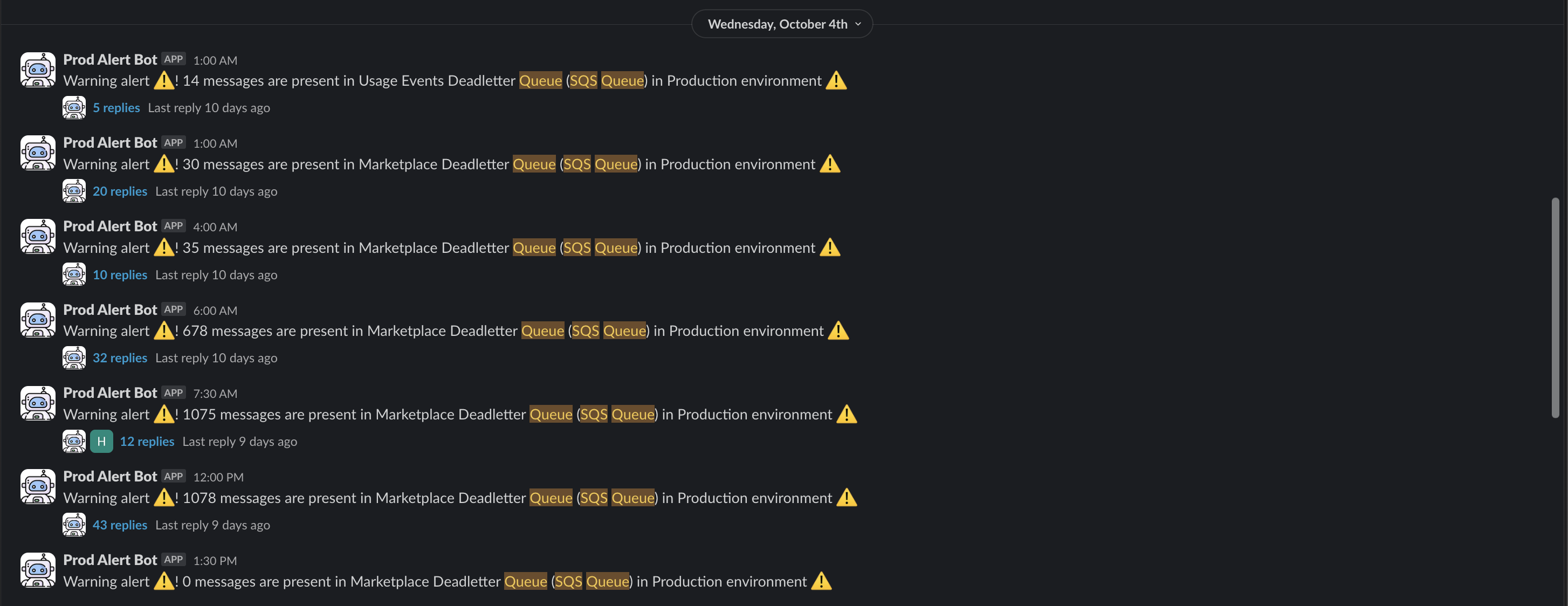
As you can see in some of the alerts, we have had thousands of messages in DLQs. Now, the developers of the system have to look at the messages to understand what went wrong. This was a tedious process. Initially, I think the developers just looked at a few of the messages and debugged the issue and understood or assumed that most issues were due to that hence the thousands of messages. But, can one be sure? No, because this checking was done manually and only for a few messages. So, we knew we can do better
I came up with a very simple idea. So, we were already having the list of messages in the DLQ. The message bodies of messages that couldn't be retried. Some of these messages were also being shown in the slack alerts just to give an idea of the top/recent messages in the DLQ. I recommended the developers to add metadata to these messages, with information about the issue - what caused it, any stack trace, and any information we have during the time of processing the message when the errors occur.
This way, we were able to add metadata like reason and error-stacktrace to the messages in our DLQ. AWS SQS has a way to add metadata - using message attributes. More information can be found here - https://docs.aws.amazon.com/AWSSimpleQueueService/latest/SQSDeveloperGuide/sqs-message-metadata.html
Using the reason metadata, developers were able to inject human-readable pre-defined reasons (or errors) for the messages that were in the DLQ due to failures. Adding the error stacktrace also helped us understand the exact place in the source code where the error occurred
Not just this, with this metadata, we could pull all the messages in the DLQ and start processing it to understand the unique list of reasons for the errors in processing the messages. We built tools around that - for example, tools to dump and delete SQS messages - https://github.com/karuppiah7890/sqs-dump, https://github.com/karuppiah7890/sqs-delete. We also built tooling to reingest messages from SQS into our NATS system - https://github.com/karuppiah7890/publish-to-nats. The reingestion was important to reprocess the messages - after fixing any issues in the system so that our customers don't face any issues due to these issues of processing messages
This idea helped us manage and work with hundreds of thousands of messages in DLQs and process them using tools and figure out various unique reasons for the errors in messages and also tooling to help with reingesting the messages after fixing any system issues




