Self hosting GitHub Actions Runners

K
I like learning new stuff - anything, including technology. I love tinkering with new tools, systems and services, especially open source projects
Search for a command to run...
I like learning new stuff - anything, including technology. I love tinkering with new tools, systems and services, especially open source projects
No comments yet. Be the first to comment.
inodes is a concept in Linux. Oh wait…no Fun fact that I learned while experimenting on my macOS - I can see that the term and concept of inodes exists in the context of macOS too Looks like it’s a “Unix” thing and Linux and Darwin, both are Unix bas...

You can look for Kubernetes Preemption Events in your observability system assuming you are exporting your Kubernetes Events to some store like some time series DB or similar In our case, we use Prometheus and we have an exporter for exporting the Ku...

Recently, when I discovered the py-spy profiler took for Python, I also discovered Speedscope, which is visualization tool for visualizing performance data (performance profile etc). This is a flamegraph Visualization. I have something of this sort w...

So, today, we had an issue in one of our internal systems called API Tester. It was very slow. Only today it was slow, and the CPU usage was very high according to our monitoring systems, especially since today morning. Before noticing the CPU usage,...

If you have Prometheus running and scraping metrics - You can find Kubernetes list of features enabled information for every feature using kubernetes_feature_enabled metric which gives build information kubernetes_feature_enabled{} The name of the f...

We at Togai use GitHub for source code management. We heavily use the Pull Request (PR) feature. PRs are kind of the main and only feature we use in GitHub. The next feature we have heavily started to use is GitHub Actions :D
We are still at a nascent stage in terms of Continuous Integration (CI) and Continuous Delivery (CD). I'm looking forward to the time when we reach Continuous Deployment for some of our services - where a git push - pushes the code, triggers build and runs all the checks (all kinds of tests) and then automatically deploys the code to production, all automatically :D
I'm not going to go into the details of why CI/CD etc. This post is about how we chose GitHub Actions as our CI/CD platform and use it as much as possible as any code-related automation platform to run code for automation
In the past I have used quite some CI/CD systems, not all of them to the same level, but to a good extent like running basic jobs. Some of the CI/CD systems I have used are GitLab CI/CD, CircleCI, Travis CI, Jenkins, GoCD, Prow CI/CD and many internal build systems for example a few in my previous stint at VMware
The thing is - I wanted a good CI/CD system - that provides a good experience and has all the basic features that anyone would want and even a few complex features. Since we already use GitHub as our source code management platform, I chose GitHub Actions and quickly implemented it - it didn't take much time to write the workflow (pipeline) YAML files (config files) - which was mostly the same for most of our services. I later optimized the workflow YAML files to reduce duplication and reuse code, and GitHub has features to do that too (Reusing workflows). Anyway, the experience was great - implementing it and using it - it was a breeze until someone sent me this picture on Slack -

The developers were saying that GitHub Actions was not working anymore. I realized that I had to face the problem that I put away in the back seat 💺 long ago. So, at Togai we use a TogaiHQ GitHub Organization and we have many private git repositories under it. GitHub Actions is free and unlimited for open-source repositories (public repositories) only and not for private repositories under GitHub Organizations (because - of course, they have to earn 😅). We at Togai are still using the GitHub Free plan only. This is because we are still small and have no need to move to a paid plan since we don't want those paid features for now and can live without them. Also, when you are running a business, a newly funded startup, you have very limited funding and we all have limited resources (time, money, energy) in general, so you try to optimize and reduce wastage in general. So, we are also trying to be very frugal, or else we will be burning 🔥 too much money 💰 💴 💵 💶 💷 💸 🤑 when we should be trying to get more customers and make lots of profit.
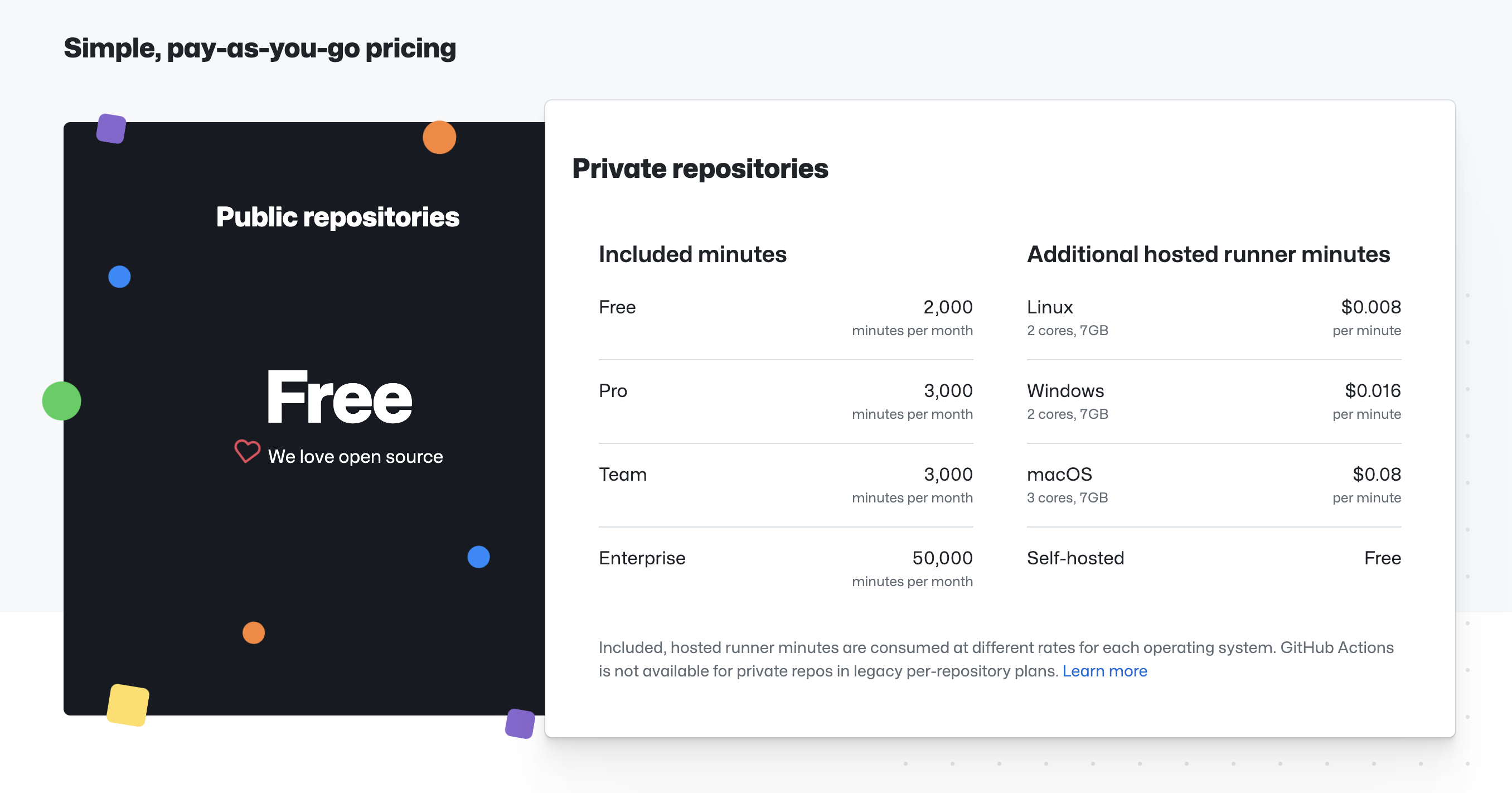
So yeah, GitHub Free Plan, along with private Git repositories under our GitHub Organization. Based on the current GitHub Actions pricing, we have 2000 free minutes per month across all the private repositories under the GitHub Organization. 2000 free minutes is around ~33.33 free hours. It was good enough for us for some time - even when we were pushing to different branches a lot of times, and GitHub Actions Workflows get triggered on push to some git branches, like main and push to PR. And PRs get updated so often and they could also get overwritten (git push --force), which will all trigger runs in GitHub Actions. I remember one of our new joiners, when they were an intern, said "Maybe we should not run for PRs. We just have 2000 minutes 😅". And he was right - as in - running for PRs is a high cost, given the number of changes happening in PRs. But the thing is this - it's an important thing to do. One cannot always expect developers to run build, test, lint etc. locally before pushing to the PR branch. For people who do it, great, for others, their code has to be reviewed with some basic reviews, and this is also for people who missed running tests by mistake. Also, running in GitHub Actions managed Runners would mean pristine environments. Okay, we are now entering the territory of why CI/CD systems are a good idea 💡 compared to doing the build, test, release, deploy etc. all in the local system
Let's get back to the main thing - so, running workflows for PRs was important. And the constraint was that we had a fixed limit on the number of minutes of workflow run. Maybe one optimization that can be done is that just before someone approves the PR, the PR's latest code should have gone through the workflow (test etc.) at least once and passed. Maybe this can be introduced as a manual trigger rather than an automated trigger after every git push which is causing a lot of workflows to run. This is a small optimization one can do. Kubernetes project's GitHub repositories, for example, use the Prow CI/CD system which has a way to provide commands to it through GitHub comments with some special characters that are treated as commands to Prow and they use this to run tests - through a manual trigger. See this here for an example
Anyways, so, that's one idea 💡 for the future - to reduce the number of workflow runs and hence to reduce the number of minutes used for workflow runs so that we use less and only when needed and do not have any unnecessary runs. But it's hard to define and figure out which runs are unnecessary. For example, if I'm sure I'm going to force push to a branch at some point, I would rather wait till I do everything, including the force push and then I'll trigger the workflow run
Even if we did the optimizations, we were going to hit the 2000-minute limit at some point. So, leaving the optimizations, we wanted to run GitHub Actions beyond the 2000 free minutes we got. We wanted to use the 2000 free minutes per month too, because, why not? :P So, we got into researching what we could do given we had already decided we would self-host GitHub Actions Runners. I just decided to stick with GitHub Actions because
The experience of using it is great! And smooth
It's simple and easy to use and understand
I didn't wanna maintain a complete CI/CD system, which is huge
The last reason is an important point. Why I don't wanna maintain you ask? A classic CI/CD system will have servers, which is the control plane that will assign jobs to workers, and it will have workers that run the jobs. There will be a mechanism to implement and use a cache to speed up builds, run tests etc; there will be a mechanism to interact with the version control system, which is GitHub in our case, and it will also have an artifact storage space - for example S3 is a popular example. There should also be the maintenance of logs, and one has to consider what is the data retention - for logs, statuses about very old pipelines, artifacts etc. Or else they will live forever and make the system storage bigger and bigger and harder to maintain. Also, who will pay for all that storage? Also, there's compute, for which we have to pay too, and then there's network too, which is usually priced high in some cases - for example for using the Internet; Maybe people won't charge for private network usage. Also, don't forget that you need to have a database for this CI/CD system - either you run it, or you get a managed instance. Both are gonna be costly - either self-host and management cost or Database as a Service cost.
So, when you maintain a CI/CD system, you have to do a lot. Even if the system is built by someone else - for example, in my last stint at VMware we tried to self-host and run Kubernetes-based Prow CI/CD in our infrastructure and I remember how much of a struggle it was - as Prow was complex. So, even if you have open source and/or free CI/CD software, running them is not gonna be a piece of cake, unless they built it with operations in mind, for example, any system operations, maintenance (upgrades), scaling up and down, configuration management etc and ensured that those operations were easy to do by a single human or small team of 3 or 4 or few developers
I didn't wanna do so much maintenance work. And I'm the only one working with Infrastructure in Togai. So I chose GitHub Actions, which looked like a good idea
So, now, with 2000 minutes per month, and the plan of self-hosting GitHub Actions Runners, what are the cost implications? And is it better than using the GitHub-managed runners? These are the questions I had in mind
So, I was checking out the cost of Linux GitHub-managed runners, which we were using and saw it's $0.008 per minute. At first glance, this may look pretty cheap. Also, if we were to use 4,000 minutes of workflow runs in a month, the first 2,000 minutes would be free, and the remaining 2,000 minutes would cost $16, the calculation will look like this -
2000 x $0.008 = $16
That seems like a small cost for one month. But let's not forget, CI/CD systems are something developers generally use often. As we scale at Togai, the code will be pushed more often, and there will probably be more services/microservices in the future and hence more git repositories as we don't follow a monolithic repository concept as of now, and on a whole we would have more code and more things happening leading us to use more CI/CD, meaning more minutes used. Also, the first month we used GitHub Actions, we reached 2000 minutes in two-thirds of a month and the next month we reached 2000 minutes in one-third of a month. But we can't say the same for next month, it could be more, or maybe even less. But in the long run, I think it will be more, as I said before - as we scale, more code etc. So, more minutes means more cost for GitHub-managed runners
Now, what's the cost implication of using self-hosted GitHub Action runners? It's free. But, it's hard to believe, because nothing is free usually 😅 . So, what is free here? I understand I am running my own self-hosted GitHub Actions runner somewhere - the cloud, my local laptop, or some on-premise data center or private cloud etc, and I pay the cost of running that machine that powers the GitHub Actions runner software. So I'm paying for the compute, network and storage costs for running the machine running the self-hosted GitHub Actions runner. What about the GitHub Actions features - the Graphical User Interface (GUI) on the GitHub website, and the storing of logs, what about all of that? Looks like it's all free! 😳 So, this means that - in the case of GitHub Actions - the control plane is free, and is hosted and managed by GitHub, and the control plane tells runners (basically workers) about what to run, and if the runners are managed by GitHub, you pay for it. If the runners are yours, you don't pay GitHub a dime to GitHub. But the GitHub Actions control plane, GUI and other related niceties come along for free, and you just pay to run your self-hosted runners. How cool is that? 😁😄😀 To know more about the exact cost of running GitHub Actions Self Hosted Runners on your own AWS Infrastructure, check the end of this blog post
Let's see how we have implemented self-hosted GitHub Action runners at Togai and the different iterations that happened
I was thinking about how to go about the implementation. I had a few ideas. I have seen one interesting setup at VMware for an open-source project where we wanted powerful machines and instead of using GitHub's managed large runners, we were running our self-hosted runners on AWS EC2 instances. GitHub's managed large runners are a pretty new feature and seem a bit costly too 😅. I don't know why GitHub-managed large runners weren't chosen at VMware - maybe it wasn't even known/considered, or maybe it wasn't available at the time. Anyways, the open source project where we needed powerful machines for CI was Tanzu Community Edition and one of the release engineers in my team wrote a small service using Golang, which would receive webhook calls whenever there was a workflow run and then the service would create self-hosted runners on-demand using AWS APIs on AWS and then kill the runner once the workflow was complete - regardless of if it was a success/failure
I loved this idea of on-demand self-hosted runners. On-demand as in - get them only when you need them, on-demand and then terminate them after using them.
I was planning on using this long-running service behind the scenes at Togai too, but I realized that I'll have to open up an endpoint, write an API, put access control around it (Authentication, Authorization too maybe) and then have rate limiting and blocklisting IPs too, to avoid any spam from the Internet. All of these were not done at VMware, at VMware they just used a hardcoded key for authentication I think, between the repository webhook caller and the API
Given the complexity of the above solution, I have put it off for later. So, the first thing I did was, look at other solutions for a quick implementation. There were some recommendations by GitHub themselves which had two big projects. Since we aren't using Kubernetes as of now, I chucked out the project based on Kubernetes. We do plan to use Kubernetes shortly, so we might come back to this decision and revisit it to check if we need to change things. The other project was based on Terraform which we do use, but the architecture seemed pretty complex, with Lambda and a lot of other services to do things. I wasn't sure about the cost of this infrastructure. Something to come back and visit. I was looking for a simple solution, as simple as possible. One of the prominent solutions I noticed was - https://github.com/machulav/ec2-github-runner
I quickly used https://github.com/machulav/ec2-github-runner and was able to see that the self-hosted runners were getting created on demand and then running tasks and then getting stopped, similar to the idea 💡 mentioned in the repo - on how it's supposed to be used
Note that when I say on-demand instance, I'm talking about AWS On-Demand EC2 Instance. Other instance types are Reserved Instance (RI) and Spot Instance. When I say on-demand runner, or creating runners on-demand - I'm referring to the ability to run runners on-demand, like, whenever you need it and only when you need it, and then destroying it once it's used. I wanted to keep that difference clear or else it could get confusing
Let me explain how the self-hosted runner works, and the concept behind it. So, GitHub manages the GitHub Actions control plane and gives an agent software to run on the worker nodes which will run the CI/CD tasks. This agent is available publicly as an open-source software over here - https://github.com/actions/runner. This agent is the GitHub Actions Runner software. We refer to the runner software as the runner software and the machine running the runner software as the runner machine
Initially, since we had used up all the free minutes in a month, we ran a long-running runner machine at the TogaiHQ GitHub Organization level, which could be used by any of the repositories under the TogaiHQ GitHub Organization
The process that started and stopped EC2 instances (servers) with self-hosted runners on-demand, was running on this long-running runner machine. In the future though, we expect that we will use the free 2000 minutes on the process that starts and stops the self-hosted runners and also for any small automation work that takes a few moments or a minute or two. Once these 2000 minutes are over, we will go back to using long-running self-hosted runners for running small automation work, and to start and stop self-hosted runners.
Initially, we had used EC2 instances in a private network as GitHub Runner machines, and these machines had access to the Internet, and hence the GitHub APIs to connect with the GitHub Actions control plane. Internet access was possible through an AWS NAT gateway. In discussing with my CTO, he mentioned that the cost of running an AWS NAT gateway was high - because it's a managed service, running NAT software to do NAT (Network Address Translation). Look below to find the pricing of NAT Gateway
As of this writing, the NAT gateway pricing is available at https://aws.amazon.com/vpc/pricing/. Screenshot below -
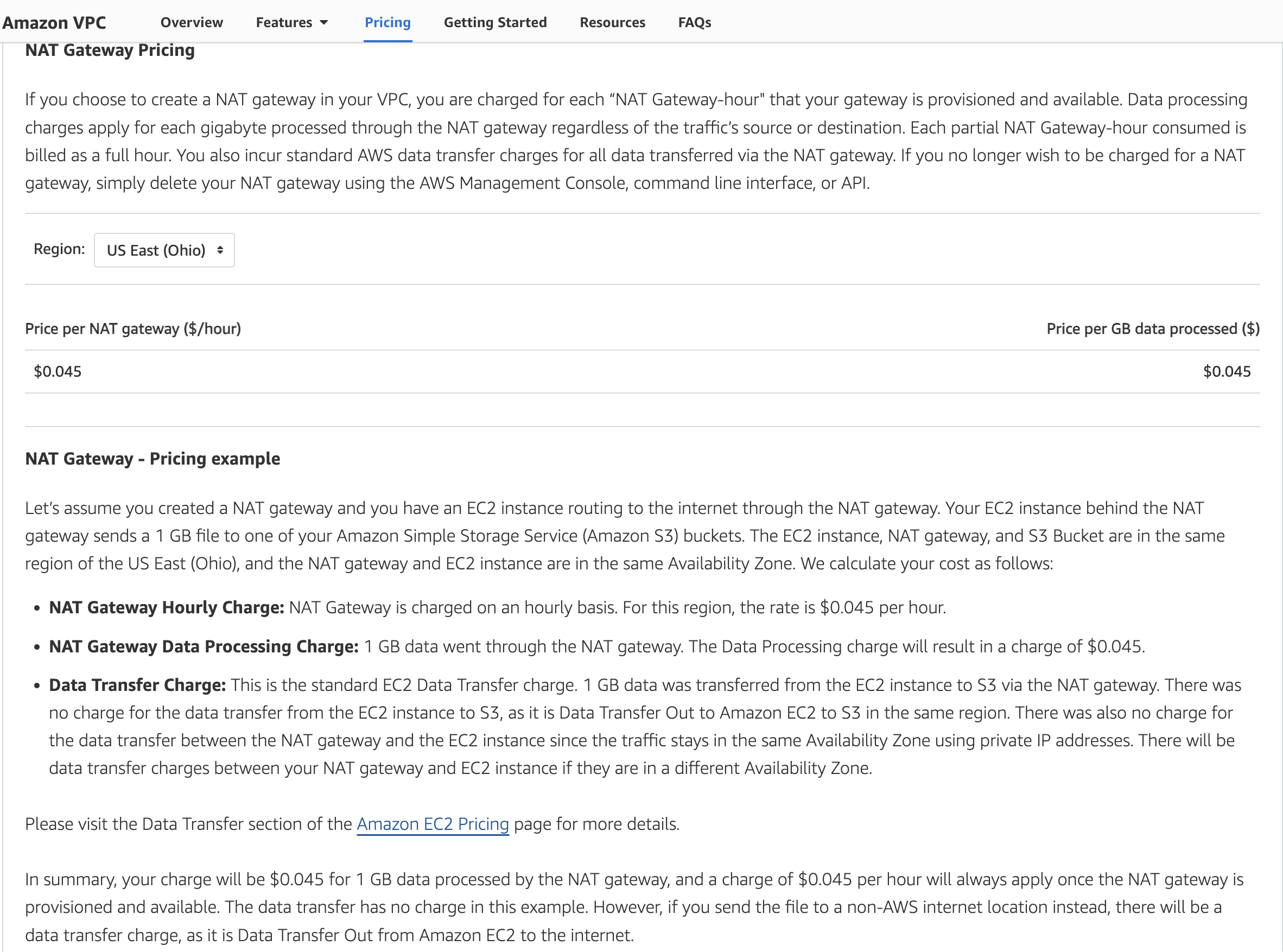

So, for this reason, I removed the usage of NAT gateway from the architecture and instead assigned public IPs to the EC2 instances running the GitHub Actions runner, so that they have access to the Internet.
You can refer to all the Terraform Code and GitHub Actions Workflow YAML code over here - https://github.com/karuppiah7890/github-actions-self-hosted-runner-terraform. It's all standalone and will work by itself ideally
The repository also contains the architecture diagram and sequence diagrams in code form and image form. Yes, code form - diagram as code ;) Let me still put the images over here
AWS Infrastructure setup diagram -

GitHub Actions Self-Hosted Runner Working Sequence Diagram:
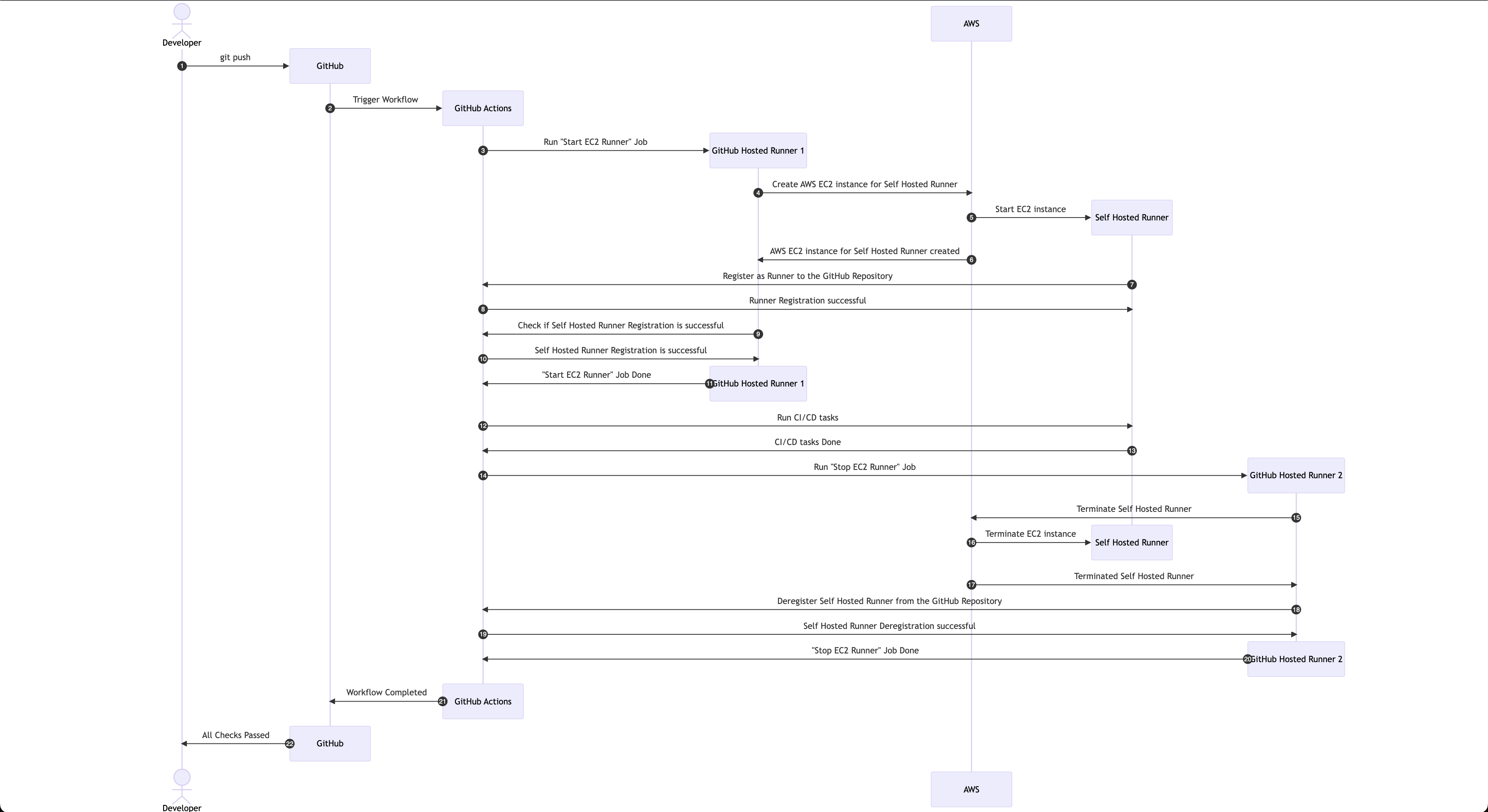
The way it works now is it's a three-step process
Step 1: Start AWS EC2 GitHub Self-Hosted Runner instance. This process runs on a GitHub Hosted VM
Step 2: Run the actual CI/CD job on the AWS EC2 GitHub Self-Hosted Runner instance
Step 3: Stop the AWS EC2 GitHub Self-Hosted Runner instance. This process runs on a GitHub Hosted VM
Now, there were quite some issues and PRs in the https://github.com/machulav/ec2-github-runner/ repo. Some of the issues and PRs made sense. For example, the ability to use spot EC2 instances - https://github.com/machulav/ec2-github-runner/issues/5. And there was a PR too for this - https://github.com/machulav/ec2-github-runner/pull/62. Noticing some of these issues, for example, https://github.com/machulav/ec2-github-runner/issues/128 and more, I went ahead and created a fork of the repo here - https://github.com/karuppiah7890/ec2-github-runner/. You can see the different changes I made here - https://github.com/karuppiah7890/ec2-github-runner/commits, like ephemeral runners, assigning public IP to the runner instances, allowing spot EC2 instances to be used given a parameter and some more small stuff
It wasn't / isn't all rosy though 😅 Let me talk about different issues we have faced till now.
One of the prominent issues is - the job not getting picked up for a long time. We still haven't found the root cause of this issue though. One guess we have is - this could be because the runner software installed in the EC2 instance is not compatible with the GitHub Actions Control Plane API. But this issue happens only at times, so, incompatibility issues only at times. I know that sounds weird. I'll post here if and when I find the root cause. The one solution to that is - to always install the latest GitHub Actions Runner software whenever the EC2 instance is created on demand, by using user data script. The code for getting the latest version can be injected here - https://github.com/karuppiah7890/ec2-github-runner/blob/d4c1e82c47b704ece2166bffa05b6316816962a8/src/aws.js#L15. It hasn't been done yet, as of this writing ✍️
The other issue was that - when using spot instances, sometimes spot instances were not available and this was clear in the error shown in the logs, an example -
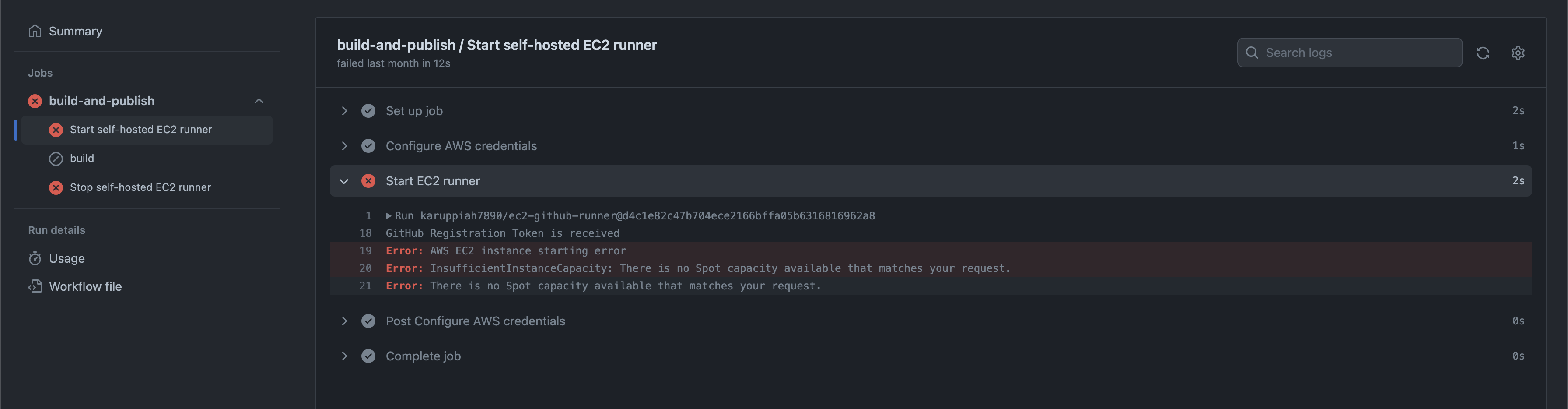
The solution for this is to retry - and create a spot instance in another region or availability zone
There are also some possible flaws in this system. Since the creator and the destroyer of the on-demand EC2 instance is the workflow itself, it's possible that an instance gets created but doesn't get destroyed due to some reason - for example, the destroy task doesn't run due to some reason like workflow canceled and aborted, etc. To avoid any zombie EC2 instances hanging around, basically EC2 instances running and not being used and being a waste - we decided to kill EC2 instances that are missed as part of termination. How did we do this? We simply defined a timeout time for any running EC2 instance that's a GitHub Action Runner machine and killed it (terminated it) once it went beyond the timeout time. For example, the current timeout time is 30 minutes. This is all done automatically by a small simple tool that I wrote - https://github.com/karuppiah7890/ec2-killer - weirdly it finds EC2 instances running in a particular VPC with a particular security group and kills only them. We use a separate VPC to run just the GitHub Actions Self Hosted Runners and separate it from other workloads - like our microservices, database (PostgreSQL), message broker (NATS), caching server (Redis) etc
The killer requires some permissions. The IAM policy attached to the IAM user used for killing the zombie EC2 instances is -
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "ec2:TerminateInstances",
"Resource": "arn:aws:ec2:ap-south-1:032794201922:instance/*"
},
{
"Sid": "VisualEditor1",
"Effect": "Allow",
"Action": "ec2:DescribeInstances",
"Resource": "*"
}
]
}
A note for people who are trying to implement this solution - ensure that the permissions for the GitHub token are appropriate and correct. You can find the token and permission details in the repo itself. The same thing goes for the access of the AWS credentials. Also, use an AMI image with appropriate software installed in it. Refer to the README here - https://github.com/karuppiah7890/github-actions-self-hosted-runner-terraform/blob/7e5334099e935432f540d4f029e239880293d709/github/README.md
Where is the code present for all of GitHub Actions Self Hosted Runner implementation in Togai?
As I said - We use a fork of https://github.com/machulav/ec2-github-runner repo. The fork has some subtle changes - fixes, a few upgrades, and a few new features that we need at Togai. It works well and we have seen it work. Fork is here - https://github.com/karuppiah7890/ec2-github-runner/
For the Amazon Machine Image for the runners / EC2 instances, we have created a custom Amazon Machine Image on top of the Ubuntu 22.04 LTS base image, along with git, docker, jq, unzip, zip installed. It also has the GitHub Actions Runner application installed
aws CLI installation because AWS CLI is a client of AWS and could keep changing to accommodate new AWS APIs and we can’t keep changing the Amazon Machine Image and keep releasing those new images to all workflows for every new version of AWS CLI. So, we just install aws CLI as part of the workflow. git, docker, jq, unzip and zip is less likely to change - especially for the features we use. But if they do change, we have to create a new imageThe cost (with the calculation) of this whole setup in Togai has been mentioned below and how it compares to the GitHub Hosted Runner Cost. We chose a particular AWS region and particular instance types to keep the cost low. The cost may vary based on your decision of which instance to choose
So, let's answer the question - what’s the average per-day cost of the current setup?
Assuming 20 pipeline runs per day per repo and each pipeline run is 10 minutes long, which is 200 pipeline minutes per day per microservice repository, and 10GB egress (data out) data transfer on a whole per day, the cost per day is around $5.22. After February 1, 2024, the cost per day is around $5.31. See below for the complete calculation
Note 1: We have 6 microservice repositories
Note 2: For the number of days per month - we use 30 when using it in the denominator in our calculation. And we use 31 when using it in the numerator in our calculations. This way, we get the upper bound value / higher value
AWS Resources used that have a price (Price as of 24th August 2023) and are not free:
| Instance name (type) | On-Demand hourly rate | On-demand per-minute rate | vCPU | Memory | Storage | Network performance |
| t3a.small | $0.0123 | $0.000205 | 2 | 2 GiB | EBS Only | Up to 5 Gigabit |
| t3a.medium | $0.0246 | $0.00041 | 2 | 4 GiB | EBS Only | Up to 5 Gigabit |
| t3a.large | $0.0493 | $0.000821666666667 | 2 | 8 GiB | EBS Only | Up to 5 Gigabit |
AWS EC2
Price per On Demand Linux EC2 instance per hour in Asia Pacific (Mumbai) Region (ap-south-1), along with instance details, for the types of instances we currently use is listed in the above table
As of today, 24th August 2023, we use t3a.small instances for pipelines in 2 service repositories
Given 1 service, assuming 20 pipeline runs per day, so 20 EC2 runners and each pipeline EC2 runner runs for 10 minutes (600 seconds), cost per day is = 20 x 10 x $0.000205 = $0.041. This is the cost for 200 pipeline minutes per day for the 1 service repository
We have 2 services here, so the cost per day is = $0.041 x 2 = $0.082
As of today, 24th August 2023, we use t3a.medium instances for pipelines in 1 service repository
As of today, 24th August 2023, we use t3a.large instances for pipelines in all ktor services in private repositories, which is - 3 services
Given 1 service, assuming 20 pipeline runs per day, so 20 EC2 runners and each pipeline EC2 runner runs for 10 minutes (600 seconds), cost per day is = 20 x 10 x $0.000821666666667 = $0.164333333333. This is the cost for 200 pipeline minutes per day for 1 service
We have 3 services here, so the cost per day is = 3 x $0.164333333333 = $0.493
AWS EBS from https://aws.amazon.com/ebs/pricing/
We use gp2 General Purpose SSD Volumes
The price is $0.114 per GB-month of provisioned storage in ap-south-1 AWS region
We use 15GB for the volume that’s attached to the instance
Price we pay per month for 15GB storage = 15 x $0.114 = $1.71
Price we pay per day for 15GB storage = $1.71 / 30 = $0.057
Price we pay per minute for 15GB storage = $0.057 / (24 x 60) = $0.0000395833333333
The price we pay per day for 1200 minutes (200 per repo per day, for 6 repos) of 15GB storage = 1200 x $0.0000395833333333 = $0.0475
AWS VPC
Public IPv4 Address (with effect from February 1, 2024). From https://aws.amazon.com/vpc/pricing/ > Public IPv4 Address tab and from https://docs.aws.amazon.com/vpc/latest/userguide/what-is-amazon-vpc.html#pricing
Hourly charge for In-use Public IPv4 Address $0.005
Hourly charge for Idle Public IPv4 Address $0.005
We have 1 Public IP per pipeline
Price we pay per minute for 1 Public IP = $0.005 / 60 = $0.0000833333333333
Price we pay for 20 pipelines per repo per day, with 10 minutes per pipeline, with 1 Public IP per pipeline = 20 pipelines x 6 repos x (Price of 1 Public IP per minute x 10 minutes) = 20 x 6 x $0.0000833333333333 x 10 = $0.1. This is the same as the price we would pay per day for 1200 minutes for using 1 public IP
Network
Accessing the Internet. Data Transfer Charges
Data Transfer OUT From Amazon EC2 To Internet
AWS customers receive 100GB of data transfer out to the Internet free each month, aggregated across all AWS Services and Regions (except China and GovCloud). The 100 GB free tier for data transfer out to the internet is global and does not apply separately or individually to AWS Regions.
First 10 TB / Month, the cost is $0.1093 per GB in ap-south-1 AWS region
Surely we won’t cross 10TB / Month for now
Will we cross the 100GB free limit? Yes. The data transfer out actions / upload actions that we do that cost us are
Upload and store Pipeline Artifacts in GitHub servers
Upload and store cache (i.e. write to cache)
In Ktor services
Currently, this happens only on the default branch, like main
As of today, per pipeline, the cache size can be as big as around 700MB, so that can be the max cache size that can be written to / restored from
We have 3 ktor service repos and on an average 20 pipelines running per day in each repo, so, assuming all 20 pipelines were run in the main and not on PRs that’s 3 x 20 = 60 pipelines per day, so that’s 60 x 700 MB per day = 42000MB per day = 42GB per day. That’s 31 x 42GB per month = 1302GB
In Node.js services
For one of the services ~= 60MB per pipeline and on average 20 pipelines running per day, so that’s 20 x 60MB = 1200MB = 1.2GB per day. That’s 31 x 1.2GB per month = 37.2GB
Other services - No additional cost as they don’t save any cache or restore from the cache - based on the pipeline run logs
Since we know we will go above the free 100 GB, let’s look at the cost for a month and then for a day. The cost per month is = total GB of data transfer out x $0.1093 = (0.186 GB + 1302GB + 37.2GB - 100GB) x $0.1093 = 1239.386 x $0.1093 = $135.4648898 . The cost per day on average is $135.4648898 / 30 = $4.51549632667
The free AWS resources we use
Network
Accessing the Internet. Data Transfer Charges
Data Transfer IN To Amazon EC2 From Internet
Data Transfer OUT From Amazon EC2 To Amazon S3
i.e. Upload to AWS S3
So, the cost per day till February 1 2024 is (without cost for Public IPv4 address) =
EC2 cost for 6 repos for 200 pipeline minutes per day per repo + EBS Cost for 6 repos for 200 pipeline minutes per day per repo + Network Cost per day = ($0.082 + $0.082 + $0.493) + $0.0475 + $4.51549632667 = $5.21999632667
Cost per minute is = $5.21999632667 / (24 x 60) = $0.00362499744908 ~= $0.004
And the cost per day after February 1 2024, including Public IPv4 address cost, is -
EC2 cost for 6 repos for 200 pipeline minutes per day per repo + EBS Cost for 6 repos for 200 pipeline minutes per day per repo + Network Cost per day + Public IPv4 Address Cost for 6 repos for 200 pipeline minutes per day per repo = ($0.082 + $0.082 + $0.493) + $0.0475 + $4.51549632667 + $0.1 = $5.31999632667
Cost per minute is = $5.31999632667 / (24 x 60) = $0.00369444189352 ~= $0.004
Most of the cost comes from the network cost (upload cost)
Comparing this with $0.008 per minute for a Linux machine hosted by GitHub is not an apples-to-apples comparison 🍎 🍏 since GitHub-hosted runner machines come with 7GB RAM, 2 cores, and 14GB SSD. Here we use 15GB SSD and some machines we use have 8GB RAM, 2 vCPUs (i.e. 2 cores) for some repos (ktor service repos), and some machines we use 4GB RAM, 2vCPUs for one of the services and some machines we use 2GB RAM, 2vCPUs (for 2 services)
To compare with GitHub Hosted Runners cost, we can consider all EC2 machines of the same configuration - close to GitHub Hosted Runner configuration - 8GB RAM and 2 vCPU
EC2 cost for 6 repos for 200 pipeline minutes per day per repo + EBS Cost for 6 repos for 200 pipeline minutes per day per repo + Network Cost per day = ($0.164333333333 x 6) + $0.0475 + $4.51549632667 = $5.54899632667
Cost per minute is = $5.54899632667 / (24 x 60) = $0.0038534696713 ~= $0.004
And the cost per day after February 1, 2024, including Public IPv4 address cost, is -
EC2 cost for 6 repos for 200 pipeline minutes per day per repo + EBS Cost for 6 repos for 200 pipeline minutes per day per repo + Network Cost per day + Public IPv4 Address Cost for 6 repos for 200 pipeline minutes per day per repo = ($0.164333333333 x 6) + $0.0475 + $4.51549632667 + $0.1 = $5.64899632667
Cost per minute is = $5.64899632667 / (24 x 60) = $0.00392291411574 ~= $0.004
So, the cost per minute in our case is half the cost of what GitHub Hosted Runner provides - $0.004 (our self-hosted runner cost) versus 🆚 $0.008 (GitHub hosted runner cost)
For the use case we have taken, which is 20 pipeline runs per day per repo and each pipeline run is 10 minutes long, which is 200 pipeline minutes per day per microservice repository, for 6 microservice repositories this would mean = 1200 minutes per day, so using GitHub Hosted Runners, say we have already used the free limit of 2000 minutes (around 33.33hrs), then the cost for 1200 minutes per day would be = 1200 x $0.008 = $9.6 per day
What’s the average number of pushes per month that trigger the CI/CD pipeline?
Around 5-10 on average, per day per repo. As we can see around 10 pipeline runs on average, per day per repo. We have 6 microservice repositories
Checking the total cost of running on-demand EC2 instances for GitHub Actions Self-Hosted Runners in your AWS Bill :D
We can add tags to all the EC2 instances we run and also tag other resources used for the GitHub Actions Self Hosted Runner Infrastructure, for example, Internet Gateway
For example, I added the below tags for the EC2 instances, using aws-resource-tags parameter in the Start EC2 runner step
[{"Key":"Feature", "Value":"Continuous Integration"},{"Key":"Repository", "Value":"${{ github.repository }}"}]
You can then go to AWS Billing > Billing > Cost allocation tags > User-defined cost allocation tags and then activate keys 🔑 like Feature, Repository and then later use it in your cost explorer to filter out the costs for running on-demand EC2 instances for GitHub Actions Self-Hosted Runners and other tagged infrastructure like Internet Gateway
This way, you can see the cost of your CI/CD setup using GitHub Actions Self-Hosted Runners on a per-repository basis :D Below is an example of what that looks like :)
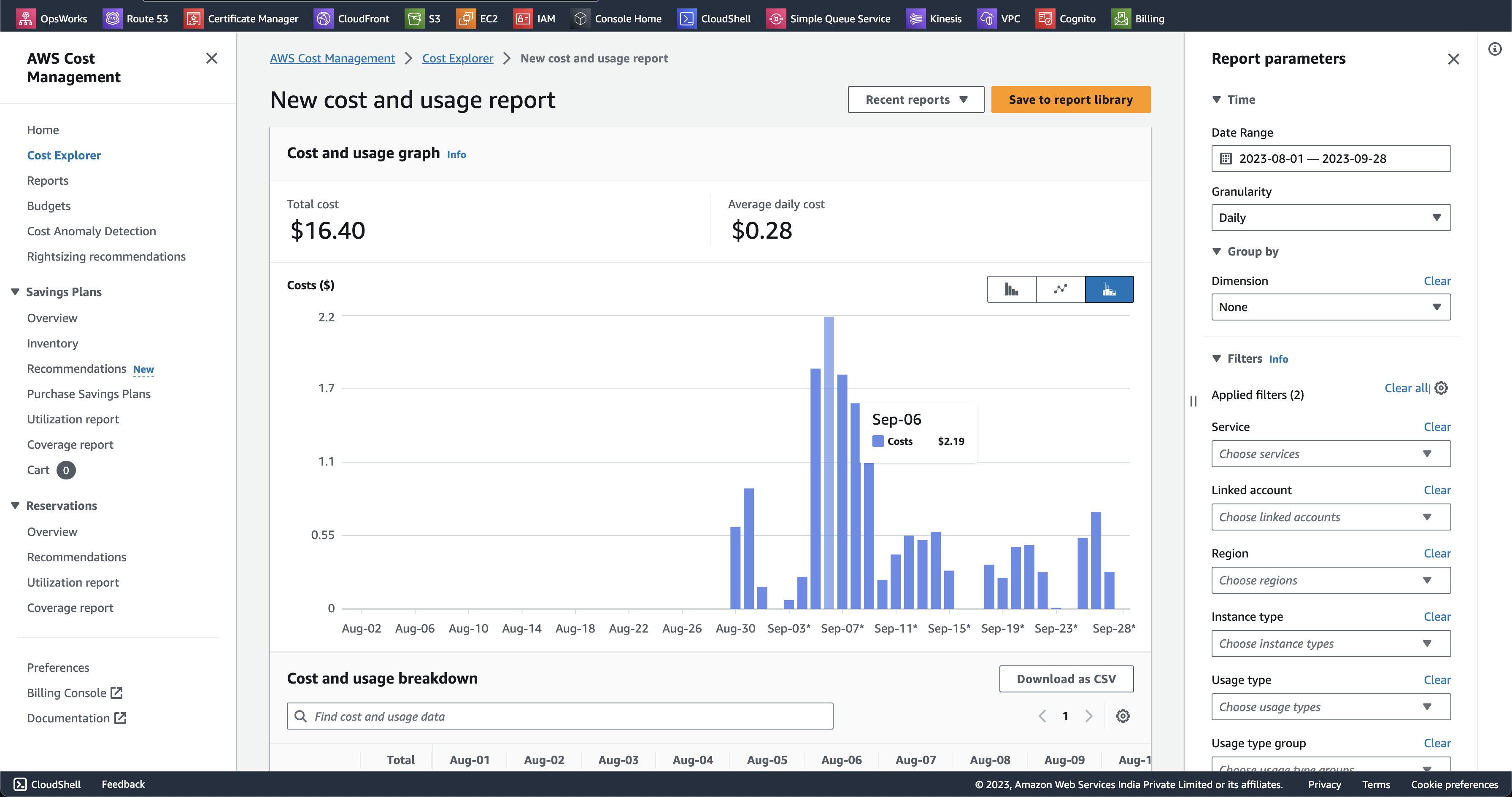
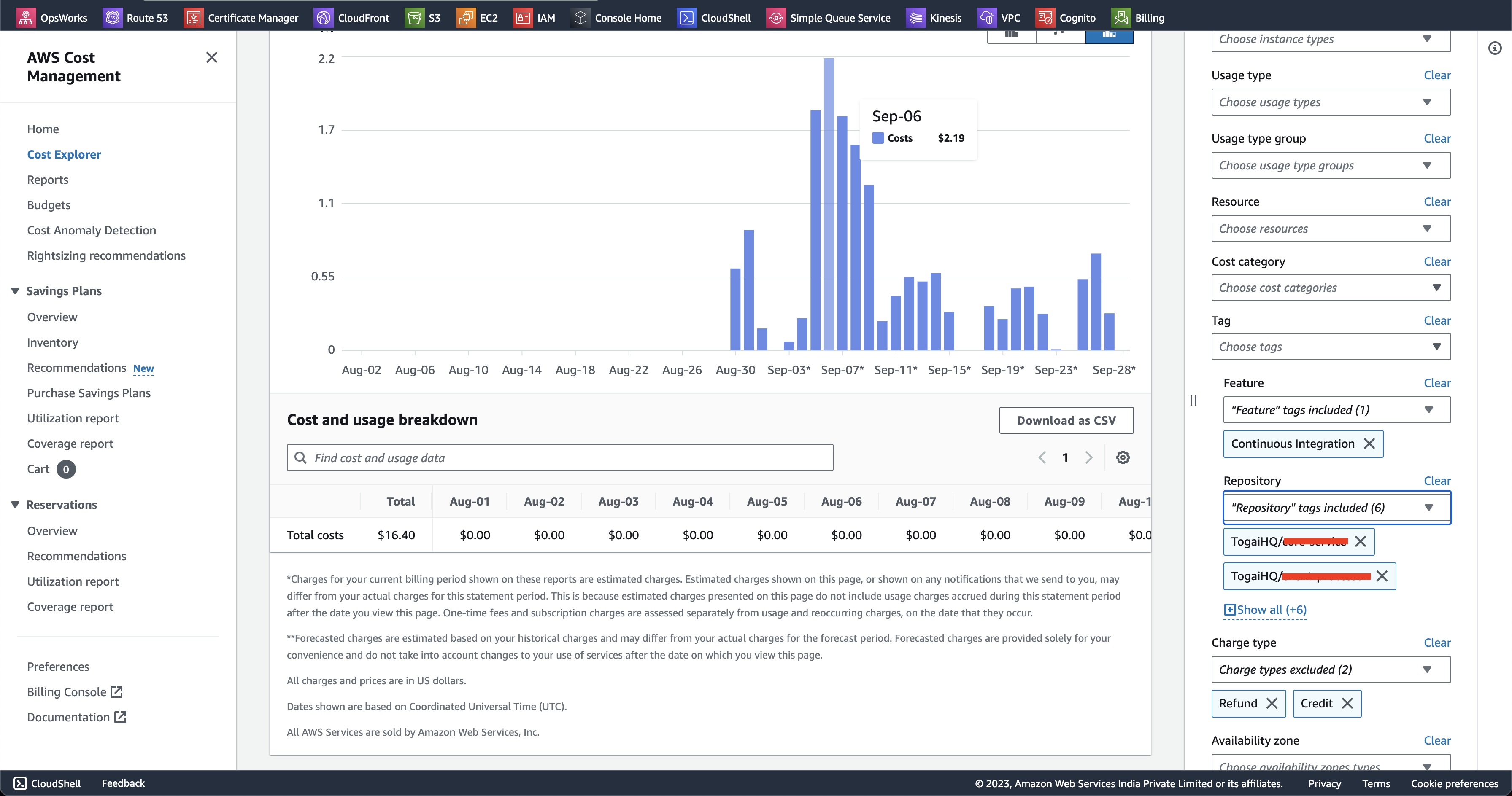
Look at the Tag 🏷️ section on the right, with Feature and Repository tag and values selected for it :D
You can add other values to your Feature key such as other prominent features of the system provided to external and/ internal users and check the cost of those :)